
-
中国行为法学会第六届四次理事会在京召开
-
沉痛悼念马宝善同志
-
中国行为法学会医疗健康法治研究专业委员会战略合作研讨会在京召开
-
学会动态 | 第二届“澜沧江—湄公河次区域”国际法治论坛在云南警官学院举行
-
[完整版|图文]《中国法治实施报告(2022)》隆重发布
-
《企业商事刑事风险防范指引丛书》 启动交流会在京召开
-
中国行为法学会侦查学专业委员会第十四届全国侦查学术研讨会暨第七届现代侦查技战法论坛在浙江绍兴召开
-
《民营经济促进法(草案)》征求意见座谈会在长沙举行
-
为人民抒怀、为时代放歌 《人民就是江山》——大型公益原创歌曲交响 音乐会在京举办
时政要闻
特稿 | 北京市广电局局长王杰群:人工智能多模态大模型技术在广电视听行业的应用现状与对策建议
内容摘要 人工智能技术是广电视听行业工业化提效的强大辅助器。当前行业面临的主要问题包括数据要素流通不畅、技术瓶颈有待突破、产业面临发展制约、安全治理面临挑战等。未来发展应以数据流通为突破口,以人机协同为核心范式,推动全生态系统性变革。本文刊发于《中国电视》2026年第1期。 文丨王杰群 责编丨杨阳 人工智能技术快速迭代,为广播电视和网络视听(以下简称“广电视听”)行业带来发展机遇。以生成式模型为核心的人工智能技术,从单纯理解信息向自主创造内容跃迁,推动行业从局部流程自动化向全流程智能化转型。其影响不仅体现在效率提升上,更深刻地作用于内容生产逻辑、工作组织体系、媒资资源观念、用户体验模式以及生态格局重组等方面。 北京市在人工智能和广电视听产业上均具备突出领先优势。北京市广电局坚持“内容+科技+安全”三驾马车并驾齐驱,推动“人工智能+视听”呈现“多点开花、全面引领”态势:主流媒体主动进行深度转型,网络视听平台发挥头部驱动作用,技术厂商引领创新与生态构建,数据与算力企业突破核心瓶颈,垂类应用企业整合工具链条,内容与终端企业重塑消费体验。 01
现状:人工智能技术是行业工业化提效的强大辅助器,而非颠覆性的创作替代者
在前期策划环节,AI大模型技术主要应用在IP评估、剧本分析、创意视觉化、文案撰写等领域。某影视公司应用自研大模型,将IP决策评估时间缩短50%至70%。某影视后期制作公司通过“AI生图—人类筛选”工序,提升视觉概念统一工效近85%;通过AI完成资料搜集、搭建框架、润色语言等,提升文案撰写效率5—10倍。某头部长视频平台将AI技术贯穿影视项目“投、制、播、宣”全生命周期。 在中期拍摄环节,AI技术赋能虚拟制片等,引领内容采集从实体场景、绿幕合成转向数字化、可交互、实时渲染的虚拟空间创作模式。神经辐射场等三维重建技术通过少量照片、视频,快速生成高精度的3D数字模型。AI算法实现光环境自动管理。XR虚拟演播室技术等大幅提升广播电视节目制作力、表现力。某影视公司探索LED虚拟制片技术,利用AI进行实时渲染和资产管理,大幅提升效率。 在后期制作环节,AI技术替代大量重复性工作。智能抠像、智能擦除技术将单帧处理时间从30分钟缩短至10—20秒。智能素材筛选实现素材自动分类、筛选和打点,缩短时间50%以上。视频生成模型快速生成基础特效片段,加速制作进程。音色克隆、多语种语音合成、高精度音画同步技术赋能国际化创作传播。北京市某区融媒体中心开展“京剧出海”声音大模型项目,高保真复现京剧表演艺术家的音色、唱腔和独有神韵,推动全球传播。 在分发传播运营环节,个性化推荐算法为用户画像,实现“千人千面”分发新范式。AIGC为广告创意生成提供工业化解决方案;AI驱动的数字人主播实现不间断商品直播。某卫视打造主持人数字IP,构建企业级Agent“超级员工”和“千人千面”栏目定制服务。 在媒资管理环节,AI多模态大模型具备的多模态数据分析、交互、语义级检索等能力加速媒资数据开发。“央视听媒体大模型”对长视频进行快速深度结构化分析,自动生成人脸识别、场景识别、全文摘要等标签。此外,AI赋能内容审核、虚假信息检测等。 在视听消费体验环节,AI技术促进沉浸式大空间(LBE)、虚拟偶像、智能硬件等视听消费发展。AR眼镜、智能电视、智能耳机等通过终端侧实时算力,提供沉浸感、个性化体验。北京某公司开发的AR眼镜,实现实时2D转3D、超分增强,优化观影体验。
02 问题:数据、技术、产业、治理多元矛盾交织,构成系统性、结构性困境 (一) 数据要素流通不畅 一是商业授权难。电影、电视剧等内容版权链条长、主体多,授权协调难度大。二是权益保护难。大模型学习数据特征并将其转化为参数,从而输出全新的内容。对于不具备极强独创性、辨识度的创作内容,现有法律框架难以精准确定、保护个人创作者权益。三是缺乏统一标准。行业缺少公允认可、标准化的数据价值评估体系,导致交易成本和不确定性剧增。广电存量数据多、历时久,非结构化、非标准化特征明显,处理成本高。四是存在“守宝”心态。数据安全风险不可控、风险收益不清晰、上级授权和指导不明确等因素制约数据主体共享意愿(见图1)。
●图1 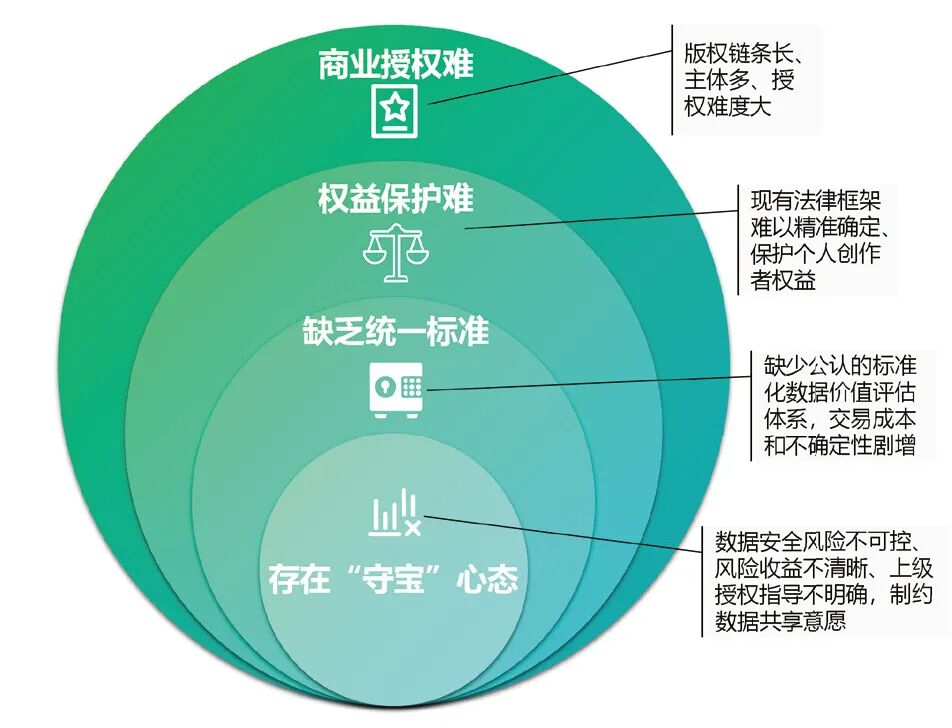
(二) 技术瓶颈有待突破 一是结果不可控。行业普遍面临“时空一致性”与“物理世界理解”挑战。某企业反映,生成视频“废片率”高达90%以上。二是交互体验差。大模型上层应用工具在交互设计、流程整合、专业指令理解上存在较大差距。三是艺术性“丢失”。影视内容独有的“艺术语言”魅力,存在于运镜、调色、合成、特效、音轨等各类型数据中。现阶段的AI大模型无法学习到“艺术数据”,导致生成的内容充满“AI味”(见图2)。
●图2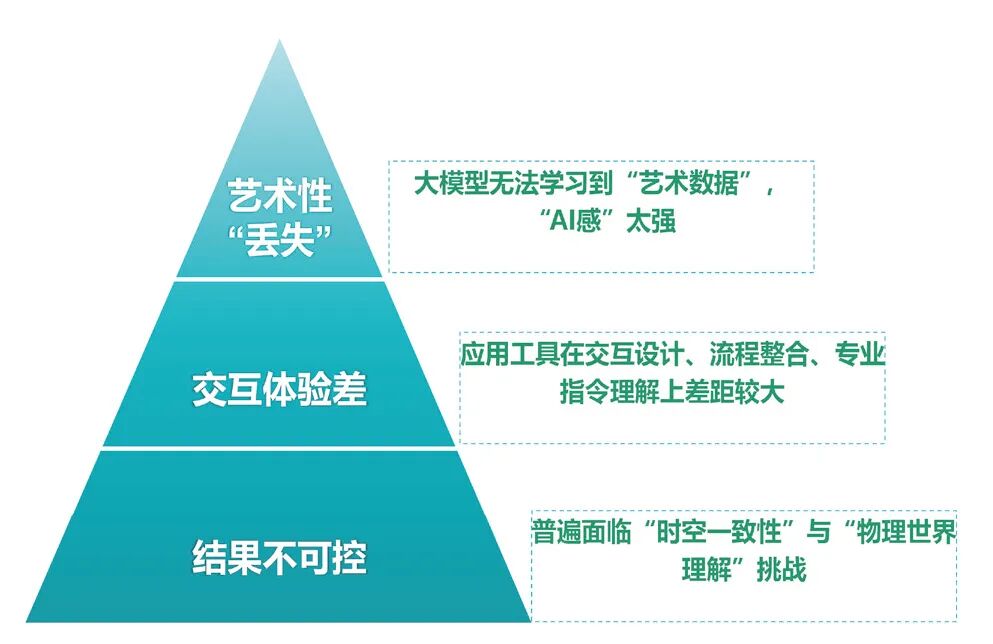
(三) 产业发展面临制约 一是市场供需错位。通用AI大模型技术研发、功能优化和商业探索均面向C端需求,以追求用户规模。广电视听行业的内容生产需求具有高度专业化、流程复杂、面向B端的特征,更需要具备一定专业能力的定制化模型。行业用户反映,主流AI工具功能强大,但总是“搔不到痒处”。二是中小主体算力负担重。下游应用层厂商主要整合调用多种第三方模型API,以提供解决方案。其核心运营成本是向上游大模型厂商付费,一般以Token数量或时长计费。以生成15分钟的AI短剧为例,综合考虑工具选择和试错成本,企业反映负担较重。此外,AIGC服务预付费制、生成结果不确定等因素导致费用支出难以符合现有体制内单位预算申报与审计制度。三是复合人才紧缺。精通内容艺术与大模型应用技术的复合型、“翻译官”型人才紧缺,导致行业专家的经验无法被有效地转译给AI大模型,迟滞智能化进度(见图3)。
●图3 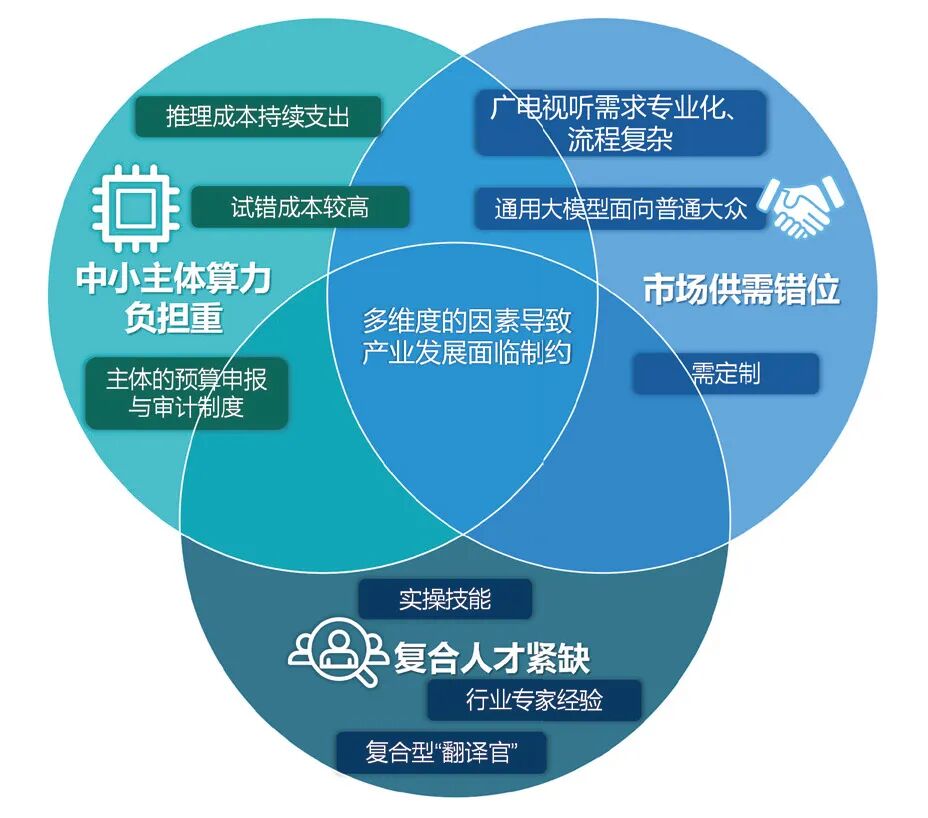
(四) 安全治理面临挑战 一是AI大模型的数据“黑箱”特性,构成隐私泄露风险。如在训练阶段对数据无感采集,可能包含未经用户明确知情同意的个人信息等;在推理阶段,用户在使用大模型服务时输入的内容也可能被用于进一步优化训练。二是AI大模型的输出“幻觉”、深度合成、虚假信息以及“文化敏感性”不足等问题,是保障内容安全必须应对的挑战。三是算法偏见、信息茧房以及对人类主体创造性价值的“贬值”冲击,形成更深远的伦理风险。
03 对策:以数据流通为突破口,以人机协同为核心范式,推动全生态系统性变革 (一) 推进数据流通和数据资产化 一是引入数据沙盒促进流通。需要将“监管沙盒”机制引入广电视听数据管理领域,构建广电视听数据沙盒,打造北京视听产业数据可信空间;选择纪录片、动画片等作为首批入箱的数据类型,开展小切口工作试点;促进数据提供方、平台方、使用方资源对接,树立一批数据提供、处理、标注、交付、使用、确权收益等全链条管理案例。 二是探索推进数据资产化。需要推动广电视听行业机构、企业探索数据资产化路径,逐步提升对媒资数据清洗、结构化、多维度标注等的处理能力,探索“保底+按Token分成”新型商业模式;鼓励头部企业围绕全国一体化数据市场、京津冀特色产业链,发展数据资源、数据资产、数据产品等多类型数据流通交易。 三是构建数据全周期处理“北京路径”。需要开展媒资数据价值评估与资产入表标准化流程专项研究,探索建立一套具备一定市场公认度、科学合规的数据价值评估方法论与资产入表操作指南,在数据资产成本计量、价值评估模型、数据入表操作流程、配套制度政策等方面提供“北京路径”;培育广电行业高质量数据集综合服务平台,支撑高质量数据集一站式采集、加工处理、质量评估与服务。 四是构建行业高质量数据集。需要加快建设行业高质量数据集,解决数据重复处理、高质量数据不易获取、处理成本高等难题;构建行业数据供需联盟,建立统一、高标准工序,将分散的行业原始数据转化为高质量公共数据产品。例如,选取“北京地标与文化符号”“中国电视剧经典对白”等作为首批建设方向,采取“众包处理+专家审核”的加工模式,建立“贡献—使用”的良性循环机制;探索数据集供给“结对子”模式,引导数据企业和人工智能企业“点对点”开放使用。
通知公告
- 暂无相关记录!